

The 2026 AI Tech Stack: Why "One Model Fits All" is Dead
Discover how AI has shifted from one-size-fits-all to specialist models in 2026. Learn to choose the right AI for (vibe-)coding your crypto apps: speed, cost, or intelligence.

The strategic approach to using AI is changing. Unlike in the early days, when 'foundation models' like ChatGPT were used for almost everything, pursuing that same strategy is now not enough. And why is that, you might ask?
Because the AI sector has fractured into specialists and the era of one-model-fits-all is over. What exists instead is the early navigation of an AI ecosystem where different models excel at different tasks and can be complemented by each other.
In this article we offer insight into this shift and make an analysis of different AI models, to help crypto developers know where to start in choosing a suitable model to build their applications. The step before beginning to write code is what tools to use. We discuss the metrics used here for classification of AI models where they excel in terms of intelligence, speed, cost, and context window.
From Generalisation to Specialization
Even before the rise in popularity of generative AI, choosing a specific AI model for a specific task was the key step to an effective outcome. But the launch of ChatGPT in late 2022 and its popularisation brought a wave of 'general-purpose' AI models that enabled the public to perform different knowledge tasks with one single model.
You could write smart contract code, create marketing plans, summarise whitepapers, and much more.
But as times changed, this approach also changed and showed some flaws. For example, a generalisation as this is more prone to mistakes, costly to train, and requires huge computing power and energy, making it challenging to scale.
A few years later, since 2025, the AI industry unfolded towards a more 'right-sized' approach, where every AI model has its own speciality. As seen in the rise of trends such as Small Language Models (SLMs), which are faster, cheaper to run, and easier to tune for specific domains, unlike Large Language Models (LLMs).
Another trend is model routing, where a user's request is automatically directed to the most appropriate AI model based on specific criteria like cost, speed, or task complexity.
Or one that is called 'mixtures of experts' or MoEs, which is an AI model architecture that comprises several specialised 'experts' inside a single model. For any given request (prompt), only the most relevant ones are activated.
Finally, as the latest trend we will discuss, we have the multi-model approach, where AI companies now develop a family of models optimised for different uses (reasoning, coding, speed, cost) instead of a single successor that handles everything.
Some examples of a multi-model approach include OpenAI's GPT-5 generation, the Gemini 3 family, Anthropic model families, and others.
The main goal of each of these trends is this: ensure every request (prompt) is performed by the most appropriate AI model. In simple terms, they are telling you:
In the same way you don't use a Ferrari to deliver groceries, don't use a 'genius' model to summarise a simple two-sentence text; instead leave that to the SLMs that cost almost nothing.
With that said, let us now look at the 2026 AI stack to see how different AI models compare and where each excels.
(Your) 2026 AI Stack
To choose the right AI model to help you build your application, you must first know its properties to determine whether it will really serve your needs.
Please note that the data used to classify these AI models comes from multiple sources and is based on different metrics.
The ‘Brains’: High-Stakes Logic and Coding
As we know, some AI tasks are non-negotiable in their accuracy requirements. For instance, when you're auditing a smart contract, analysing legal language, or building complex crypto systems, a simple error can result in a huge failure.
Therefore, in this case you need the 'brains' from AI models optimised for precision, reasoning, and deep understanding.
While the metrics for evaluations to rank AI models in this sector are many, five stand out as the most used to test AI models across cognitive domains. They include:
- Multilingual Massive Multitask Language Understanding (MMMLU), which measures AI's general knowledge and reasoning across 57 disciplines in 14 different languages.
- ARC-AGI-2, which measures artificial general intelligence focusing on higher-level fluid reasoning across patterns, sequences, and analogies.
- GPQA Diamond, a graduate-level Google-proof Q&A benchmark (Diamond subset), designed to test how accurately an AI model can answer graduate-level questions...
- The 2025 American Invitational Mathematics Examination (AIME), which tests advanced reasoning in mathematics across AI models.
- Agentic coding (SWE-bench Verified), which evaluates AI abilities to solve real-world software issues sourced from GitHub.
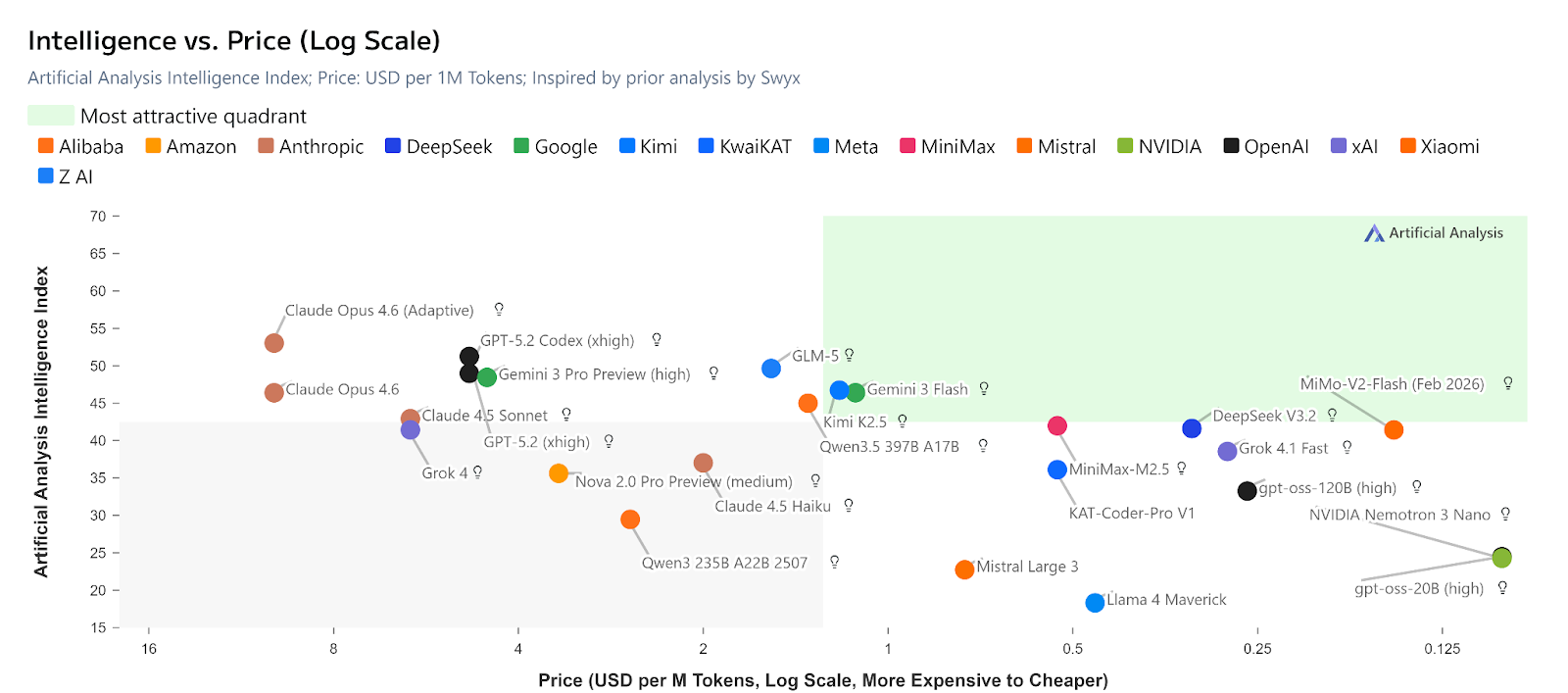
According to this data from several sources, this is how different LLMs' latest models rank in each of the above metrics as of February 2026:
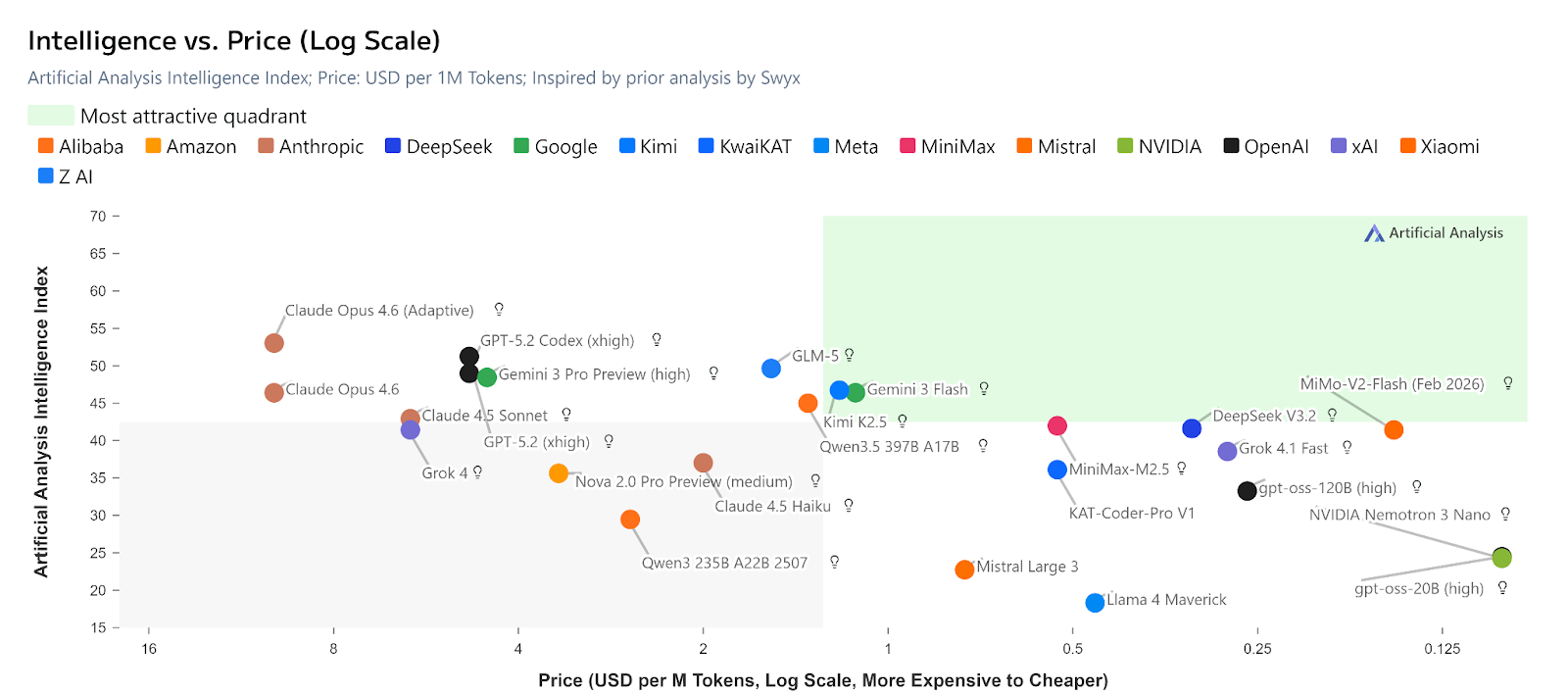
Claude Opus 4.6 and GPT-5.2 take the highest ranks in intelligence, with Claude Opus 4.6 demonstrating particularly strong performance across reasoning-intensive tasks.
But intelligence alone doesn't win; in production, the fastest response often beats the smartest one. Therefore, let us look at which models excel at speed.
The Speed Demons
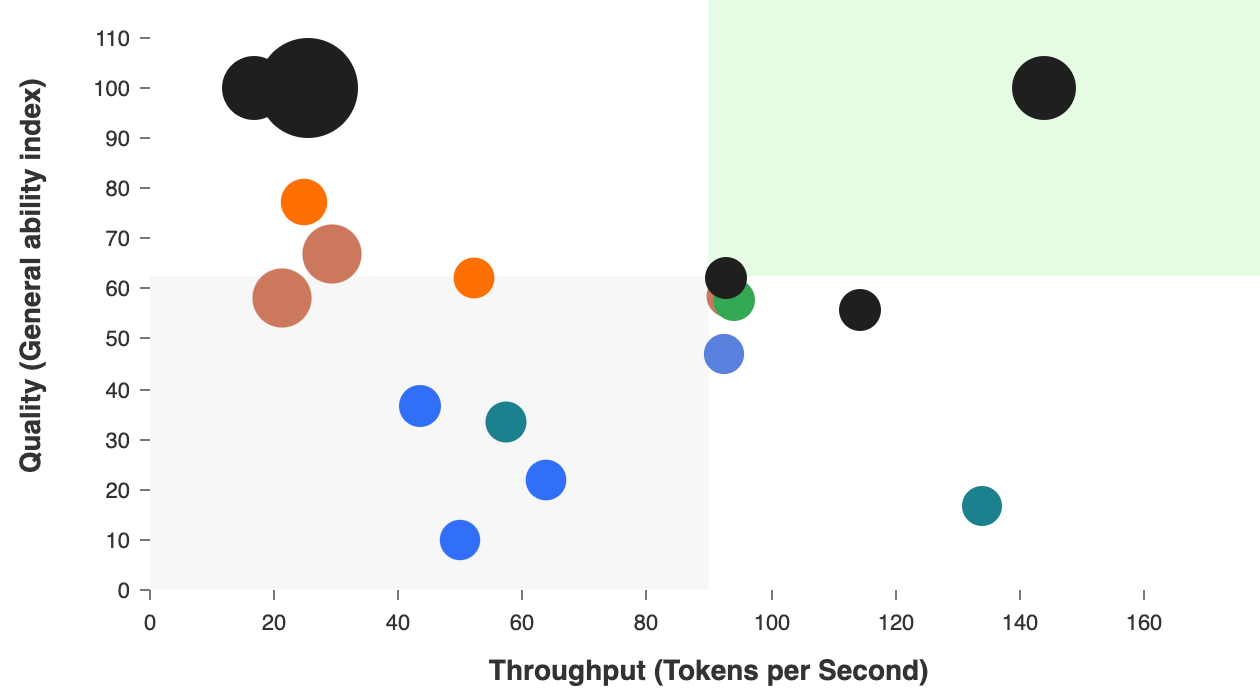
The moment you shift from building, auditing, or analysis to real-time crypto applications, the optimisation priorities reverse. Speed now becomes a priority. In this research, relevant benchmarks here are output tokens per second (OTPS), latency, and intelligence level versus speed.
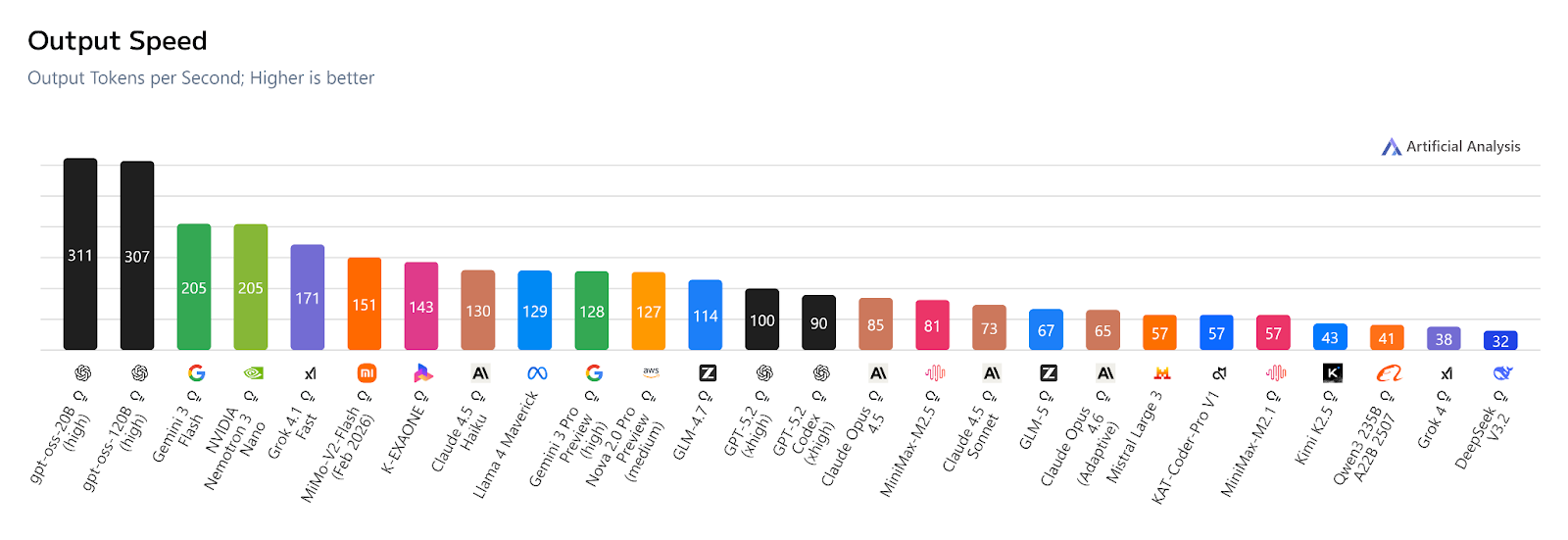
Output tokens per second measures how fast a model can generate responses once it begins responding.
According to data from Artificial Analysis, the gpt-oss family, both 20B and 120B, are the current speed champions with an OTPS of 311 and 307 respectively.
Following closely are Gemini 3 Flash and Nemotron 3 Nano, each with 207 OTPS, and so on as seen in the image below. 👇
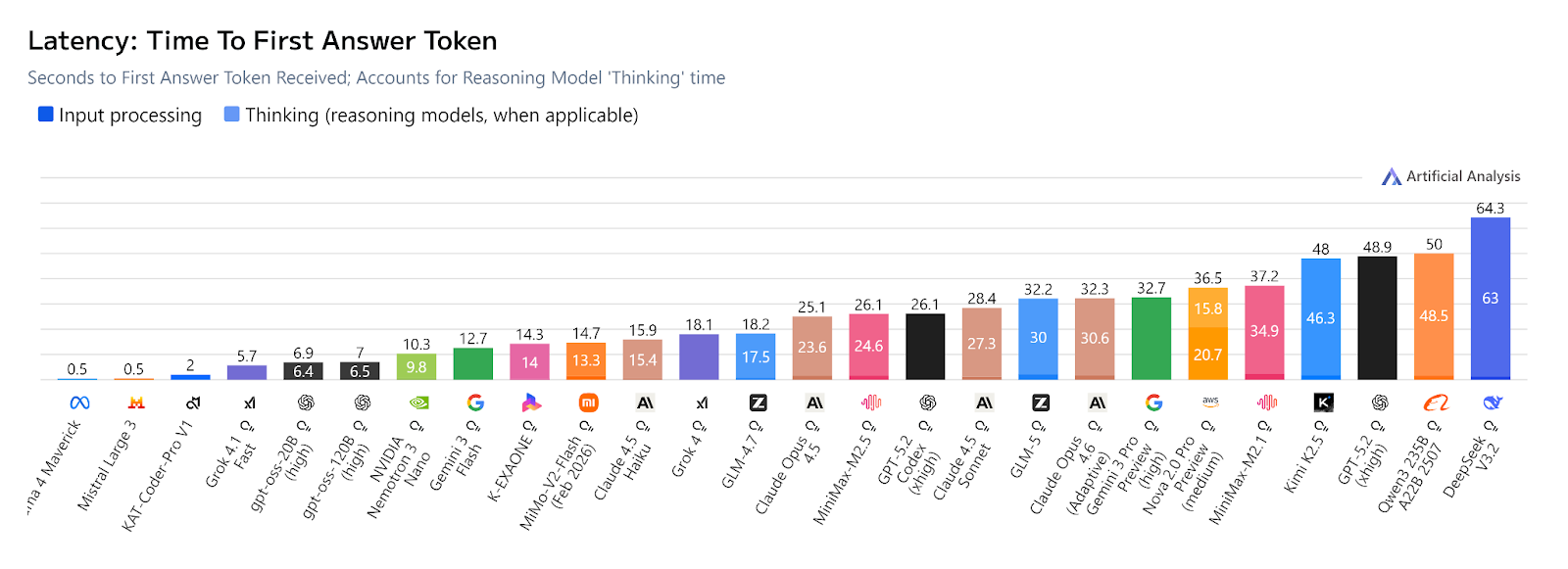
Latency, on the other hand, measures the time delay between sending an AI request and receiving a response. For reasoning models, this includes the 'thinking' time before providing an answer, which makes many fall behind in this section.
A tip: when you want faster, lower-latency responses when using thinking models and complex reasoning is not required, you can adjust the model's thinking level to low.
A look at the intelligence versus speed ratio shows higher intelligence models typically have lower output speed.
The Workhorses: Agents and Cost Efficiency
If you are building autonomous crypto agents that loop continuously, then you will definitely need an AI model with strong reasoning or intelligence benchmarks. But you need to watch how much it actually costs to do this.
Over time, AI model costs have been dropping at a high rate. Research from Stanford's Human-Centered AI Institute says that, depending on the task, LLMs can become 9 to 900 times cheaper each year.
The cost of querying an AI model that scores the equivalent of GPT-3.5 on MMLU dropped from $20.00 per million tokens in November 2022 to just $0.07 per million tokens by October 2024.
Models such as gpt-oss-20B (on high thinking) cost about $0.07 for input and $0.20 for output per million tokens. Following closely are Nemotron 3 Nano ($0.06/$0.24), MiMo-V2-Flash ($0.10/$0.30), and DeepSeek V3.2 ($0.28/$0.42), as seen in the table below.
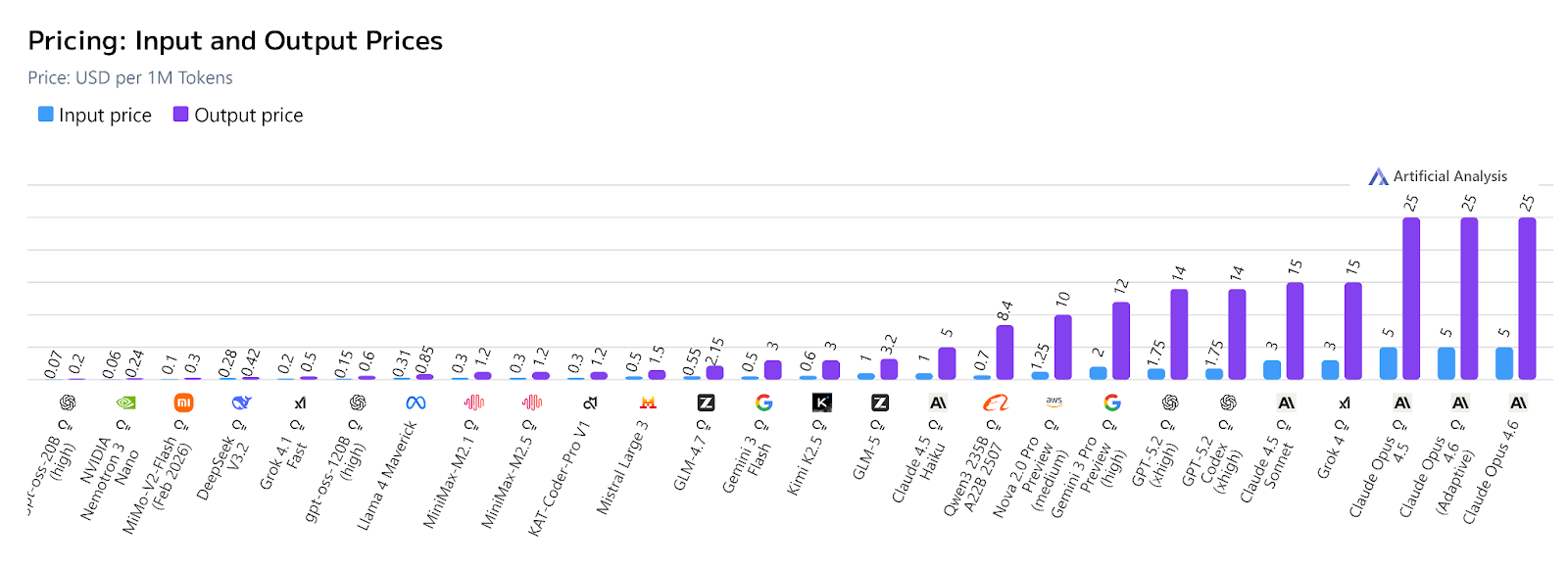
An important thing to note is that increasing an AI model's thinking level increases cost. Therefore, be keen when using 'thinking' models for simple tasks which can be performed by non-thinking models or low-level thinking may cost you.
Also, you should not mistake this for intelligence-to-cost ratio. Although higher intelligence models are typically more expensive, they do not all follow the same price-quality curve.
The most affordable AI models in 2026 include Nemotron 3 Nano ($0.06/$0.24 per million tokens), gpt-oss-20B on high thinking ($0.07/$0.20), MiMo-V2-Flash ($0.10/$0.30), and DeepSeek V3.2 ($0.28/$0.42), as shown in the table below.
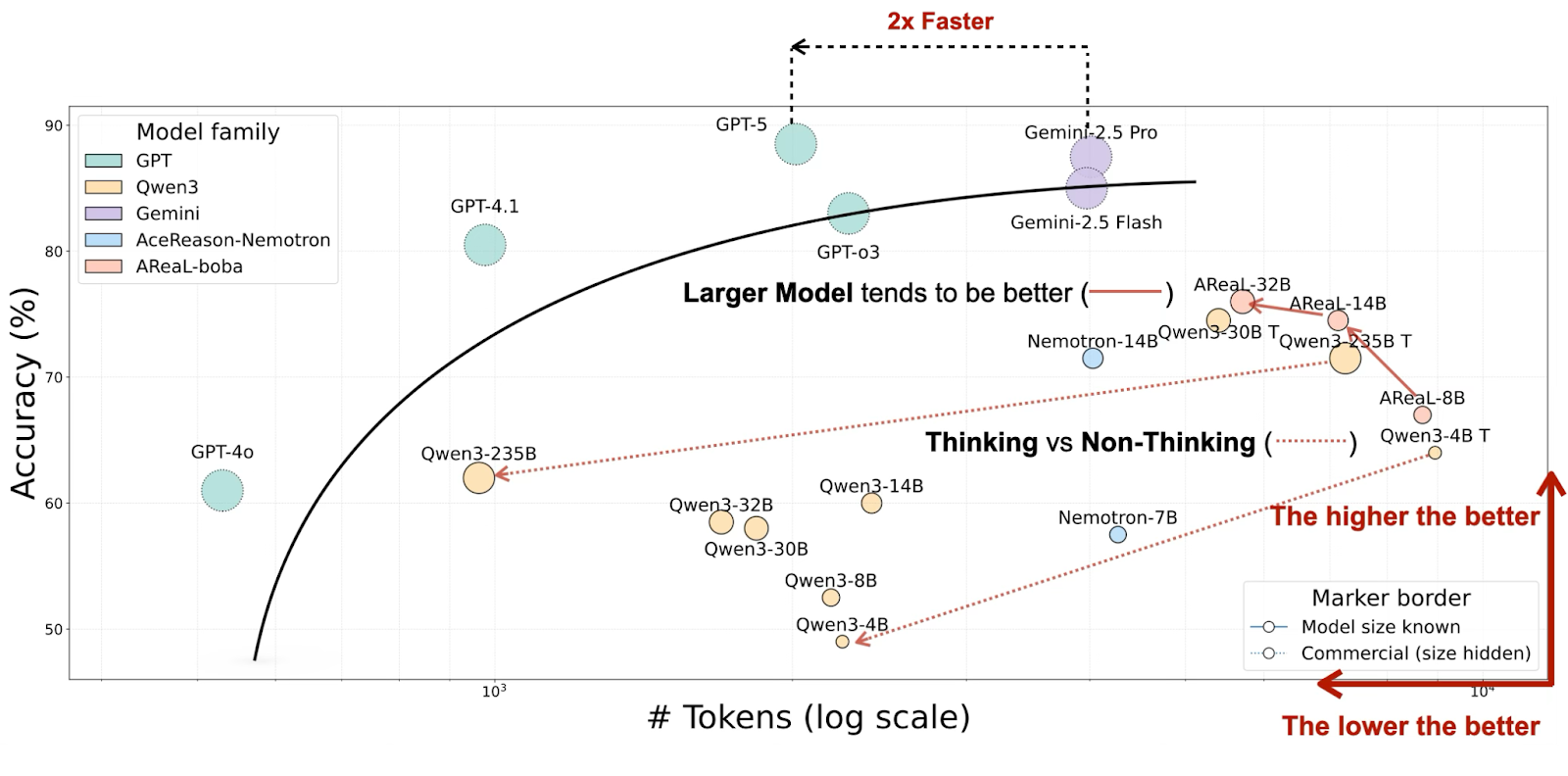
Data from OckBench '2025 Workshop on Efficient Reasoning' shows a similar trend where models with comparable accuracy and reasoning efficiency differ in token consumption. For instance, Gemini-2.5 Pro used 2× more tokens than GPT-5 for similar accuracy.
Therefore, it is upon you to choose the model that aligns with your budget and performs your task efficiently.
The Context Kings
Different AI models have different context windows, which refers to the maximum number of tokens an AI model can keep in its working memory at once.
If you are performing massive-scale codebase analysis or auditing entire contracts plus dependencies at once, then you definitely need an AI model which will be able to read all your long inputs at once.
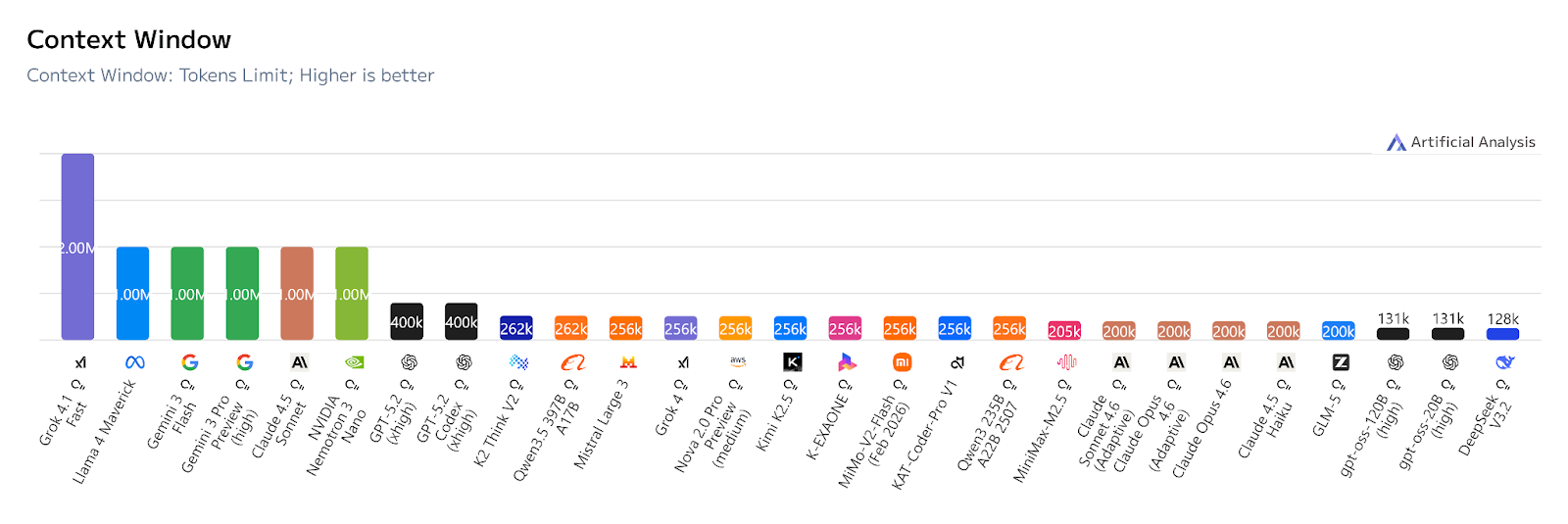
As of February 2026, Grok 4.1 Fast leads with the longest context window of up to 2 million tokens, followed by the Gemini 3 models (Flash and Pro), Claude 4.5 Sonnet, and Nemotron 3 Nano, each supporting 1 million tokens.
However, the context window alone isn't enough; we also need to see how these AI models perform with huge content. When evaluating their performance across large contexts using the MRCR v2 (8-needle) benchmark, these are the results:
☝ The percentage score shows the ability of an AI model to accurately retrieve and recall specific, identical pieces of information hidden within very long contexts.
Fun fact: A new trend known as RAG (Retrieval Augmented Generation) is being supplemented in massive context windows, where AI is allowed to overcome context-window limits by retrieving only the most relevant external information and inserting it into the model's memory before generating a response.
Beyond Text
Beyond the text models, the 2026 AI stack also comprises both image and video models. These models help you in media generation and vision analysis, to bring visibility to your crypto application.
Data shows GPT-Image 1.5 and Nano Banana Pro (Gemini 3 Pro Image) as the leading text-to-image generator models, having secured the highest votes from different users. Other notable models are Grok Imagine Image, Flux 2 (both pro and max), and Seedream 4.5.
In terms of video generation, data from the two sources shows Veo 3.1 Fast from Google, Grok Imagine Video, Kling 3.0 (both pro and standard), and Sora 2 Pro from OpenAI as the leading models.
Conclusion
Building an efficient crypto application is no longer about using ever-larger models for everything, but rather adopting a multi-model approach where you strategically choose different AI models for their specific expertise.
Master this approach, and you'll move faster, spend less, and build more safely in the evolving crypto ecosystem.
Also, follow us for more on live coding a crypto project...🦦

Connect with Bitfinity Network
Bitfinity Wallet | Bitfinity Network | Twitter | Telegram | Discord | Github

*Important Disclaimer: The information provided on this website is for general informational purposes only and should not be considered financial or investment advice. While we strive for accuracy, Bitfinity makes no representations or warranties regarding the completeness, accuracy, or reliability of the content and is not responsible for any errors or omissions, or for any outcomes resulting from the use of this information. The content may include opinions and forward-looking statements that involve risks and uncertainties, and any reliance on this information is at your own risk.
External links are provided for convenience, and we recommend verifying information before taking any action. Bitfinity is not liable for any direct or indirect losses or damages arising from the use of this information.



Comments ()